背景介绍
recsys2013 Linkedin pairwise learning的报告
观测数据:用户U产生行为Y(在linkedin场景行为是加入的社区),形成一条数据(u,y)
推荐问题:给定一些(u,y)的元组,为一个用户u推荐用户可能产生的行为(加入社区),或者一个用户u是否会加入社区y
常用方法:收集用户的profile和偏好, 计算用户和社区的相似程度
计算相识度的算法非常多, 启发式方法: 利用启发式公式,计算用户和社区的相似程度。 常用的计算相似度的方法包括:jaccard,余弦相似, 欧式距离等:
具体的方法和普通的协同过滤算法类似,定义了user * item的矩阵,计算 item-base的方法是先把item表示成user的向量,
itemA : <userA,userB,userC,userD>
itemB : <userA,userB,userE,userF>
用户以上的相似计算方法度量itemA和itemB的相似性,为了映射到itemA和user的相似性,把user表示成item的向量
userA: <itemB, itemC, itemD>
那么itemA和userA的相似性可以表示层:itemA和<itemB,itemC,itemD>的平均相似性,或者其他值
基于模型的方法 直接通过数据特征和把目标,预测用户对目标的偏好程度,常见的机器学习方法比如Logistic Regression
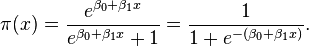
这里的x指用户和社区的特征,比如用户的性别,年龄,兴趣,社区的主题,用户和社区的特征组合等等,而目标即用户是否加入社区
一些观察
通常pointwise的排序方法就够用了,但是很多场景下,我们很难度量用户对某个item的喜好程度,但是我们可以定义一些用户的偏好; 另一方面,排序算法会利用点击日志来调整算法的效果,用户只能点击到我们投放给用户的item,用户行为表现更多的是偏向,而不是程度。
比如:在搜索结果场景中,通常会给用户展示多个候选集合,用户浏览集合然后从中挑选出自己偏好的集合。这里的用户行为实际上表现了一些用户的喜好, pointwise的假设是用户的喜好是全局的,用户对候选的表现是独立,不会受到前后的影响。而实际情况确有不同,比如用户通常会对比候选,然后挑选出一个。 因此用户的偏好常常是相对的,为了描述这种相对偏好,常常采用pairwise或者listwise的ranking方法。
对单次点击的pairwise样本:
- Click > Skip Above
- Last Click > Skip Above
- Click > Earlier Click
- Last Click > Skip Previous
- Click > No-Click Next
分析
如何结合整体点击率,在单次点击里抽样样本
- 同query下,每个item的统计CTR
- 可选择:消除position bias
- 选择CTR差值有一定置信度的Pair, 比如:A->B, E->C, C->E
- 对单次点击过滤掉行为噪音,满足购买>点击>无行为, 从每次pv中过滤掉不满足约束的Pair,剩下A->B, E->C
-
特征改进
- 按照原始特征分布去筛选样本分布
- 没有区分度的特征通过样本选择的方式去改进
- 负样本采样
- 没有最优的负样本采样策略
算法
- rankSVM
- PLSA
并行化
- GPU
- 并发
- 分布式
- BSP on MPI:
- Hadoop
- Scala