论文
recsys2013的poster[selection content-based features for collaborative filtering recommenders] [p1]
八卦
作者是 [p1]: http://www.eng.tau.ac.il/~noamk/papers/feature_selection_recsys_2013.pdf
recsys2013的poster[selection content-based features for collaborative filtering recommenders] [p1]
作者是 [p1]: http://www.eng.tau.ac.il/~noamk/papers/feature_selection_recsys_2013.pdf
recsys2013 Linkedin pairwise learning的报告
观测数据:用户U产生行为Y(在linkedin场景行为是加入的社区),形成一条数据(u,y)
推荐问题:给定一些(u,y)的元组,为一个用户u推荐用户可能产生的行为(加入社区),或者一个用户u是否会加入社区y
常用方法:收集用户的profile和偏好, 计算用户和社区的相似程度
计算相识度的算法非常多, 启发式方法: 利用启发式公式,计算用户和社区的相似程度。 常用的计算相似度的方法包括:jaccard,余弦相似, 欧式距离等:
具体的方法和普通的协同过滤算法类似,定义了user * item的矩阵,计算 item-base的方法是先把item表示成user的向量,
itemA : <userA,userB,userC,userD>
itemB : <userA,userB,userE,userF>
用户以上的相似计算方法度量itemA和itemB的相似性,为了映射到itemA和user的相似性,把user表示成item的向量
userA: <itemB, itemC, itemD>
那么itemA和userA的相似性可以表示层:itemA和<itemB,itemC,itemD>的平均相似性,或者其他值
基于模型的方法 直接通过数据特征和把目标,预测用户对目标的偏好程度,常见的机器学习方法比如Logistic Regression
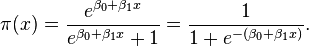
这里的x指用户和社区的特征,比如用户的性别,年龄,兴趣,社区的主题,用户和社区的特征组合等等,而目标即用户是否加入社区
通常pointwise的排序方法就够用了,但是很多场景下,我们很难度量用户对某个item的喜好程度,但是我们可以定义一些用户的偏好; 另一方面,排序算法会利用点击日志来调整算法的效果,用户只能点击到我们投放给用户的item,用户行为表现更多的是偏向,而不是程度。
比如:在搜索结果场景中,通常会给用户展示多个候选集合,用户浏览集合然后从中挑选出自己偏好的集合。这里的用户行为实际上表现了一些用户的喜好, pointwise的假设是用户的喜好是全局的,用户对候选的表现是独立,不会受到前后的影响。而实际情况确有不同,比如用户通常会对比候选,然后挑选出一个。 因此用户的偏好常常是相对的,为了描述这种相对偏好,常常采用pairwise或者listwise的ranking方法。
对单次点击的pairwise样本:
如何结合整体点击率,在单次点击里抽样样本
特征改进
| 摘要: | 本文介绍冷启动的问题以及常用的求解思路 |
冷启动问题的分类:
冷启动是稀疏数据问题一种特殊形态。用户跟系统的交互非常少,导致可以利用的数据比较小,也很难为用户建立Profile和兴趣,因此会导致一般的推荐算法失效。
冷启动问题的解决方案:说白了,就是尽可能利用信息给用户一个可以接受的物品列表,最常见的就是热门排行。
有的是根据冷启动问题分类来的,有的是从解决方案(能利用用户什么类型信息)来的。
Linear combination of regression and CF models
Filterbot Add user features as psuedo users and do collaborative filtering
Hybrid approaches Use content based to fill up entries, then use CF
http://grouplens.org/papers/pdf/filterbot-CSCW98.pdf
Good performance on Netflix (Koren, 2009)
DIVERSITY方面的相关文章 关于diversity方面的推荐系统论文,搜索了一下相关的文章,下面是一些比较著名的文章的列表
Being accurate is not enough: how accuracy metrics have hurt recommender systems
其中第3篇是第一篇有关diversity的经典论文。第二篇是去年Resys08的一篇论文,主要贡献是用线性二次优化来找到整数二次优化问题的次优解。第4篇是一篇定性的文章,主要在于diversity背后哲学问题的讨论
imrchen去年也整理过diversity方面的文章,因为他的博客大陆不能访问,不过可以访问他在CiteULike的链接:
http://www.citeulike.org/user/imrchen/tag/diversity
WI2009收录的两篇Diversity方面的论文 1. Statistical Modeling of Diversity in Top-N Recommender Systems, Mi Zhang 2. Novel Item Recommendation by User Profile Partitioning, Mi Zhang
kdd2013 google的论文就像一枚重磅炸弹 Ad Click Prediction: a View from the Trenches
##工程考虑 ##结语
| 摘要: | 主要围绕Gediminas等的论文,讨论下一代推荐系统的形态 |
讨论祖先和子孙的问题一向是比较困难的事情,什么是上一代,他们有什么特点?下一代推荐系统到底是什么?前后代有什么不一样,是什么关键特征定义了下一代? 本文的重点是,讨论一些论文观点,旨在回答以上的一些疑问 从Gediminas Adomavicius和Alexander Tuzhilin的Towards the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions来看(这篇文章引用率非常高),我的理解是:
第一代推荐系统主分三类:
第二代推荐系统的主要特点是:
Gediminas Adomavicius在推荐系统方面有很多研究, 有兴趣可以看看CAREER: Next Generation Personalization Technologies,研究主题包括:
早期的推荐系统主要是“评分预测”和“TOPN”预测,不论是哪一种推荐方式,其核心的目标是找到最适合用户c的项集合s,从集合里挑选集合是一个非常复杂的问题优化方案,通常采用的方案是用贪婪的方式,而我们只需要定义一个的效用函数,选取TOPN。
定义效用函数为:用户c和项s的内容上的”相似性”,比如商品推荐中,为了一个用户推荐一款合适的商品,会计算商品和用户历史上看过或者买过的某些特征上的相似性(比如:品牌的偏好,类目的偏好,商品的属性,商品标签等等)。很多推荐都会在有文本的实体上进行推荐,改进的主要思路是:
因此,基于内容的推荐算法的关键问题是建立,item的content profile和user的content profile。 对于有问题内容的推荐实体,一般的方法是利用关键词抽取技术,抽取item中最重要的或者最有信息量的一些text。 第一个任务是选择什么的文本,构建的text从来源上可以分成几个,如果来之item本身的内容,通常称为keywords; 如果来自用户的标记,通常称为tags;如果来之外部的query,通常称为intents。 第二个任务是如何在候选词里做weighting和selection。selection的方式一般是用贪心方法,选出topn weighting的词。
构建user的content profile是比较困难的。因为user本生是没有标记的,通常是通过user从前看过的item和当前看过的item做 标记。从时间的维度上,user的content profile可以分成历史和实时部分,历史部分通常是通过挖掘获取,而实时部分通常是 通过巧妙的”average”或者model-based的方法发现用户content profile, 比较出名的content-based推荐系统是Fab, “adaptive filtering”是一种通过user的浏览记录不断提升精度的content profile构建方式
是大家最为熟悉的推荐算法。算法只涉及到user-item的交互矩阵,推荐方式是Heuristic-based(memory-based)方法(item-based和user-based)和 model-based的方法,后面发展的一批改进协同过滤算法的策略,比如:
当然还有很多推荐系统应该解决的问题和扩展, 但是,就这样还不能是二代推荐系统的特征, 推荐系统的发展永远是围绕着“用户体验”来做的。